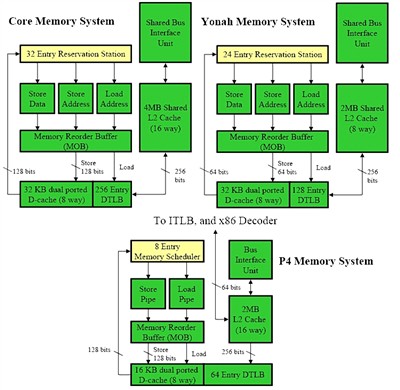
Core
微架构有着数量众多的执行单元,形成了超乎寻常的处理资源。这庞大的执行单元不仅要求前端提供更多的微指令来喂饱自己,也对存储单元的处理能力提出了更高的要求。下图是
Core 微架构、Yonah 微架构和 NetBurst 微架构的存储单元对比,注意 NetBurst 微架构利用“fast
ALU”来计算存储地址,因此并没有独立的存储地址单元。Core 微架构的存储系统源自 Yonah 微架构的设计,但是却拥有 NetBurst
微架构的超高带宽,实在是难能可贵。
Intel 三代微架构存储单元对比
Core 微架构和 Yonah 微架构的一级缓存与二级缓存都采用“写回”(Write Back)的存储方式,以64字节为存储单位。而对于
NetBurst 微架构来说,一级数据缓存采用“写直达”(Write
Through)的存储方式,以64字节为存储单位;而二级缓存采用“写回”的存储方式,以128字节为存储单位。
Intel 没有给出 Core 微架构的缓存延迟,但是其一级数据缓存的延迟很可能是2个时钟周期,最多为3个时钟周期。并且,Core
微架构中的2个核心的一级数据缓存之间有一条附加的数据通路,使得2个核心可以直接交换一级数据缓存中的数据。Intel
仍然没有给出更多的资料,这种数据交换的发生是否频繁,每次数据交换传输多少数据,一次这种数据交换是否可以替代一次对二级缓存的访问,这些都还没有答案。
Core
微架构的存储单元还拥有新的预取器设计,协同共享式二级缓存进行工作。每个核心的一级数据缓存各自拥有多个预取器。而共享式二级缓存自然是共用多个预取器,在运行时,这些预取器根据改进的“Round-Robin算法”把带宽动态分配给2个内核。共享的前端总线也采用类似的方法进行仲裁。
Core 微架构的存储系统还使用了一种新的技术来解决内存混淆问题(Memory Aliasing
Problem)。我们将在下面的部分详细介绍关于内存混淆问题和这种新的解决方案。
(责任编辑:刘伟) |